In the background, while tons of work stuff has been happening, I’ve been continuing my mission to write a fully-featured computer chess engine in the C programming language. My engine is named SpaceDog, in honour of my dog Laika, who is from space.
Work on SpaceDog has been proceeding well, with lots of additions to its evaluation function, convenience features like outputting fully-diagrammed logs of each game you play against it, outputting games in PGN format, etc. Now I’m diving into adding more substantive features, in this case support for Syzygy endgame tablebases.
Endgames have always been a prominent feature of chess study, and over the centuries millions of players have stared uncomprehendingly at difficult endgame studies, mate-in-3 puzzles, and similar things. For the improving player, endgame study is interesting but also very challenging, in that there are innumerable situations where a seemingly simple or natural move can lead to disaster, or conversely the failure to find a very specific and unintuitive move can lead to a missed win.
Naturally this is just as much of an issue for computer chess engines as it is for humans. Many engines over the years have been programmed with specific rules for winning typical endgames like KPvsK (King and pawn versus a lone king) and some of the particularly long-winded and tedious ones like KRvsK (King and Rook versus King) or the dreaded KBNvsK (King, Bishop and Knight vs King — you get it now, abbreviations only from now on!). Some of these endgames require remembering rules particular to each endgame, or even memorising long strings of winning moves in order to not mess up and give your opponent a stalemate.
Before we go any further, a quick reminder of the basic rules of ending a chess game:
- Checkmate: opponent’s King is in check (attacked) and unable to escape to safety
- Stalemate: opponent’s King is not in check, but your opponent has no legal moves, (remember it’s illegal to move into check)
- Draw: declared when players repeat an identical board position 3 times in a row, OR when 50 moves have elapsed without a pawn move or capture taking place
These rules and the complicated nature of some endgames make things difficult for humans to succeed in their endgame play, and chess engines struggle too, even when looking ahead many more moves. Let’s see, for example, how SpaceDog copes with the tricky KBNvsK ending:
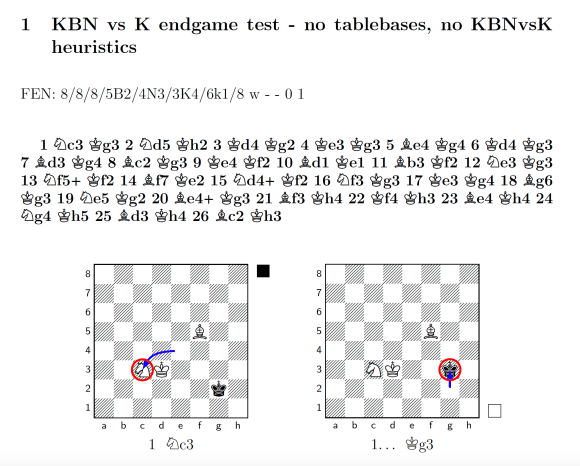
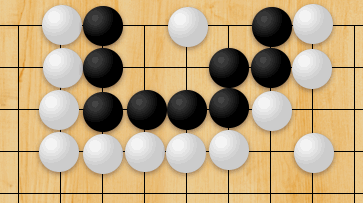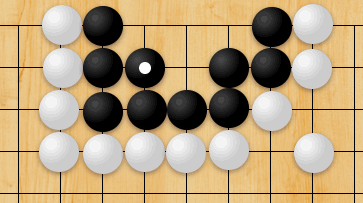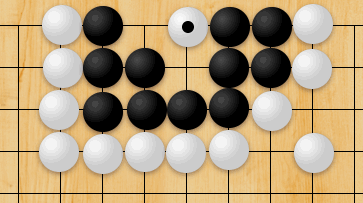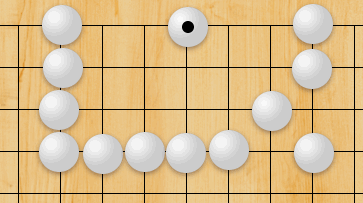
Here’s a snippet of SpaceDog’s attempt (before my recent additions) to play KBNvsK (the full PDF record is available here). I actually stopped the engine after 26 moves as it was clearly making no progress! If you check the full game log out, you’ll see that SpaceDog manoeuvres bravely, but is unable to work out the correct plan to trap the enemy King, even though it was looking ahead 25 moves at this point. SpaceDog needed to trap the enemy King against the side or corner of the board to make it easier to deliver checkmate, but couldn’t coordinate its pieces correctly, and so the ending barrelled irretrievably toward a draw by the 50-move rule.
It’s worth saying that SpaceDog, even armed with only its core evaluation function and search, is more than capable of winning many endgames. But even in those cases, it can make the occasional mistake that can allow a clever opponent to salvage a draw or stalemate, or can be simply inefficient and take longer than it should to mate the opponent. Let’s take this KPPvsKP ending as an example:
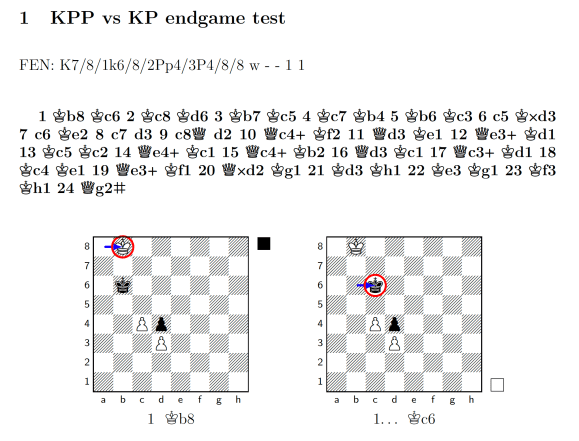 This endgame looks simple, but the black King is in the way of White’s protected passed pawn on c4, so getting that pawn to promote and become a Queen requires some finesse. SpaceDog manages this quite well without any additional help, mating the opponent in 24 moves. However, with clever play it should be possible to checkmate Black quicker and with a greater material advantage.
This endgame looks simple, but the black King is in the way of White’s protected passed pawn on c4, so getting that pawn to promote and become a Queen requires some finesse. SpaceDog manages this quite well without any additional help, mating the opponent in 24 moves. However, with clever play it should be possible to checkmate Black quicker and with a greater material advantage.
And that clever play is what endgame tablebases are all about. Endgame tablebases in chess came about thanks to Richard Bellman, who in 1965 proposed analysing chess endgames using retrograde analysis — starting from checkmate positions, and working backward from there to find the optimal moves to reach that position. The end result of this would be a massive database containing every possible configuration of pieces on both sides of an endgame with small numbers of pieces, with complete information on how to reach the best possible ending from that position. In 1977 computer science legend Ken Thompson used the first endgame tablebase in an engine against a human opponent, and from there chess engine programmers were off to the races.
Today thanks to widely available supercomputer power we have access to tablebases that enumerate all the optimal moves for both players from every possible endgame position containing seven or fewer total pieces. This is a truly staggering number of positions — 423,836,835,667,331 to be exact! Yes that’s 423 trillion positions. There are 512 billion KRBNvsKBN endgames alone! For every single one of these positions, we know: the game-theoretic value of the position (Win, Lose or Draw, or WDL for short); the distance-to-zero (moves before a pawn move or capture that zeroes out the 50-move drawing rule, or DTZ); and the distance-to-mate (number of moves for the winning side to mate, or DTM). You can explore any and all of these positions and view the winning moves and various stats about endgames at Syzygy-Tables.info; the front page also has handy links for downloading all the tablebases for yourself.
I should note that of course given the size of these databases, the actual files are very large. The best available compression algorithm for full WDL and DTZ tables is Syzygy, which is what I’ve added to SpaceDog. The 3, 4 and 5-piece endgames will take about 1GB of storage, but you’ll need 149GB for the 6-piece endgames, and a staggering 18.4TB for the 7-piece endgames! To use them most efficiently, make sure the WDL tables are on very fast storage like a solid-state drive (SSD), as these are accessed by engines very frequently to guide the engines toward favourable endgame positions, whereas the DTZ tables are only accessed once the engine actually enters an endgame position and needs to know the best moves.
So, after a weekend of work, SpaceDog can now use the Syzygy endgame tablebases, and thus plays endgames perfectly. This makes it far better for practicing endgame play, for learning difficult endgame and mating sequences, and for analysing games. To see how dramatic the change is, let’s go back to that KBNvsK endgame from earlier, where SpaceDog stumbled about uselessly for 26 moves heading for a draw, despite having a massive advantage in material. Once we add Syzygy tablebases, SpaceDog obliterates its opponent in only 7 moves:
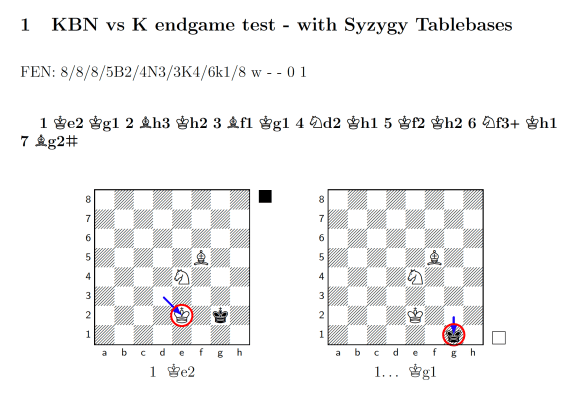
Look at that lovely short move listing! This time, SpaceDog uses all of its pieces in concert, confining the enemy King to the corner by occupying the short f1-h3 diagonal with its bishop. Shortly afterward, we end up with an effectively and efficiently checkmated opponent:

Even when we revisit endgames that SpaceDog can win easily, the Syzygy tablebases provide significant improvements. Going back to the KPPvsKP endgame from earlier, SpaceDog checkmates five moves faster:

SpaceDog not only wins faster, but it ends up with two queens instead of just one! The opponent doesn’t stand a chance:

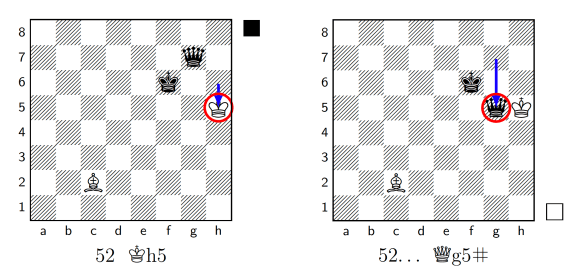
Of course these are far from the most complicated endgames available. SpaceDog can now win endgames that take potentially hundreds of moves, without making a single mistake. The Syzygy tablebases are built with the 50-move rule in mind, so in some longer endgames you’ll see clever trickery as SpaceDog just manages to make or allow a pawn move or capture before the deadline, to reset the clock and deliver checkmate later on. Take for example this KBBvsKQ endgame, in which SpaceDog achieves mate in 52 moves:
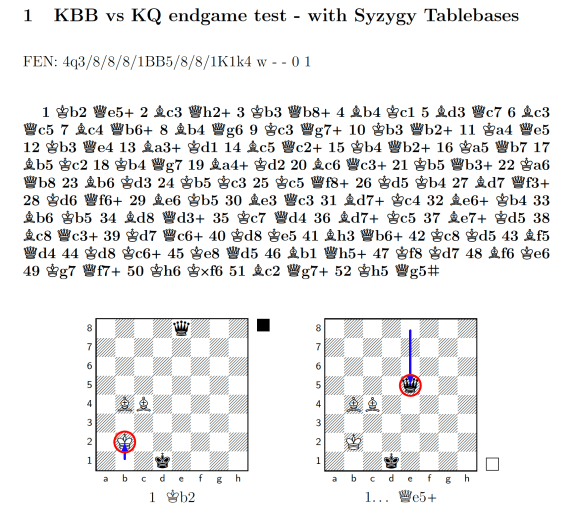
Here SpaceDog methodically manoeuvres the Queen to neutralise both of White’s bishops, until it captures one of those bishops at the last possible moment (the last half-move of move 50):
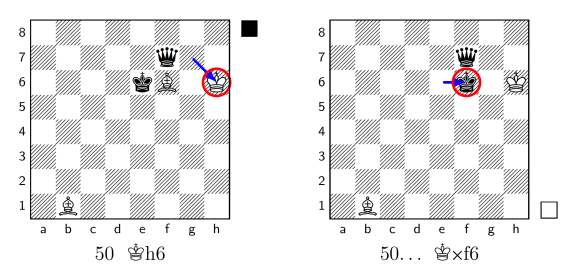
That gives SpaceDog the time to finally deliver forced checkmate two moves later:
As you might imagine, remembering forced sequences of so many moves and using them with such impeccable timing is impossible even for the top Grandmasters — there are simply too many endgame possibilities to make rote memorisation worth the trouble. Even if it were worth it, remembering sequences like that over the board under time pressure against live opponents would be a very tall order!
During my testing I found a particularly cruel example of this kind of brutal efficiency in this KNNvsKP endgame, where White delivers a tricky checkmate with two knights after 52 moves:

Note that the first move, Na2, immediately immobilises Black’s passed pawn, where it stays frozen until move 50, when White lets it run free. ‘Yay!’ says Black, ‘I’m making a Queen! I’m back in this!’
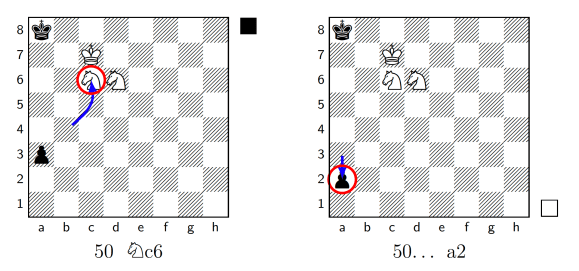
Black does make a Queen, as it happens, but it’s ultimately pointless as they get checkmated immediately:
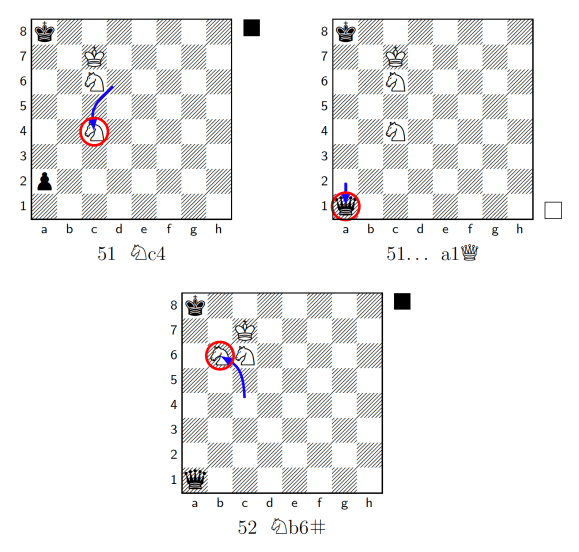
SpaceDog, that’s just harsh!
Anyway, these are just some fun examples from 5-piece endgames — there’s some amazing endgames in the 6- and 7-piece databases of course, with forced checkmate sequences lasting hundreds of moves, totally bizarre-looking moves that turn out to be the only path to win or draw, and intricate piece play that has done wonders for our understanding of endgames. I highly recommend taking a look at some cool endgames using an engine, or just browsing them via the web interface linked above — you’re bound to find something fascinating. Assuming you care about chess, obviously.
So what’s next for SpaceDog? Well first, my Syzygy tablebase support is only half-finished — endgame play is now perfect, but I have yet to implement searching of the WDL tables during midgame play to guide SpaceDog toward the best possible endgame positions. That’s a relatively straightforward addition and will take much less time than adding the DTZ support, thankfully!
After that, I’m aiming to beef up SpaceDog’s search, making it more efficient to allow searching to greater depths, and making it much faster by using multi-threading (multiple CPU cores). At that point, SpaceDog will have all the main features of a modern alpha-beta chess engine, and will make a worthy opponent for its eventual successor: SpaceDogNeuro.
You can download the latest SpaceDog executables for Windows and MacOS (Linux forthcoming, when I remember) at the Github repository, by the way, but bear in mind it’s a messy hobby project, and a major work-in-progress with bugs lurking everywhere! If I were you I’d wait for version 1.0. In the meantime, for serious chess analysis, Stockfish is the superior choice (and it’s free and open-source too).